古典籍の文字解析および字形比較のためのシステム開発
近世日本の古典籍には、ジャンルや時代により様々な字形が存在しているが、われわれの多くはそれらを読むことに困難を生じている。近世の刊本が造本デザインの視点から紹介されることが少なかったのは、古文の読解が特殊な技能となってしまったことも、理由のひとつに挙げられる。
本研究プロジェクトでは、そのような状況を改善するために、日立製作所の高速類似画像検索システム「Enra Enra」を応用した、独自のシステムの開発に取り組んだ。これにより、ある任意の文字を選択すると、形態の類似性にもとづいて、字形が登録されたデータベースから類似した字形を瞬時に割り出すことができ、さらに、古活字版、整版、写本等、条件を指定した絞り込みや出版年の範囲指定も可能となった。以下にその開発の経緯と成果について、年度ごとに報告する。
平成 26 年度
初年度は、本学美術館・図書館の所蔵する貴重書と金原服部文庫の古典籍を対象に、資料価値の評価と整理を進めた上で研究対象資料のデジタル化に着手した。本システムの開発目的を、近世の版本の文字解読補助機能と文字形象の研究とし、高速類似画像検索技術「Enra Enra」を用いて新たに開発するシステムの基本的な仕様について検討を重ねた。また、研究を進めるにあたり必要となる事前準備作業を以下の a から d に掲げた項目に整理し、作業に必要な時間及び経費等の調整を行った。
a. システムの検索項目等の検討及び開発。
b. 研究対象資料のデジタル化の方法と書誌情報の登録内容の検討。
c. システム上における文字データの切りだしと登録、読み仮名の付与等の作業を行うためのインターフェースの開発。
d. 近世版本の文字の解析補助と、文字形象の比較研究のために類似画像検索機能の精度を向上させるための、「古典籍の文字データベース」(字書)の充実。
平成27年度
研究対象資料のデジタル化を継続。また、日立製作所の研究者や技術者とも相談しながら、本システムが実現する機能の具体的な検討を始めた。高速類似画像検索技術「Enra Enra」を応用して、専門的知識がなければ読むことの難しい連綿体やくずし字等の解読を補助する機能や、文字形象の比較研究を行うための機能を盛り込んだ新たなシステムの開発と仕様の検討を開始した。10 月よりシステムのプロジェクト内での運用を始め、研究対象資料のシステムへの画像登録と登録された画像の「文字切り出し」に着手した。
なお、本システム構築のために行なっている作業手順は以下の通りである。
1. 研究対象資料のデジタル化
2. デジタル化画像および書誌情報のシステムへの登録
3. システム上での「文字切り出し」
4. 文字画像への読み仮名の付与
5. 文字画像の登録
平成 28 年度
研究対象資料のデジタル化を継続。システムのプロジェクト内での運用を継続し、「文字切り出し」を継続・推進。システムの基本仕様の開発を終えた。26年度に本研究の事前準備として策定した a から d の作業のうち、28 年度末時点において、a から c までを完了した。また、d の充実を図り、本研究の主眼である日本近世における文字形象の研究に取り組んだ。なお、28 年度末時点でシステムに組み込まれた機能は以下の通りである。
• 任意の文字形象を類似性に基づき比較研究するための「古典籍の類似字形検索機能」
• 仮名あるいは漢字の特定字種の検索機能
• 版形式(写本、古活字版、整版、近世木活字版)や出版年による絞り込み機能
上記三点の条件を組み合わせることにより、これまで構築に努めてきた「古典籍の文字データベース」(字書)から、目的に応じて的確な絞り込み検索が可能となり、システム利用者の研究目的に適った類似画像の抽出と分類が可能となった。これにより、任意の文字データに対する類似画像の検索効率が格段に向上し、近世の刊本の研究を進めるための基礎的な条件を整えることができた。
平成 29 年度
研究対象資料のデジタル化を継続。システムのプロジェクト内での運用を継続し、「文字切り出し」を継続・推進。システムの最終公開用画面の開発を終えた。26 年度に本研究の事前準備として策定した a から d の作業のうち、29 年度末にはすべての開発を完了した。
また、a から d までの準備が整ったことを受けて、29 年度末までに、新たに「古典籍の文字解析補助機能」をシステムに組み込んだ。これにより、本研究が目指していた「古典籍の類似字形検索機能」と、「古典籍の文字解析補助機能」のすべてが実装された。限定的な公開ではあるが、学内向けの公開画面が完成した。
平成 30 年度
29年度に実装された「古典籍の文字解析補助機能」により、任意の古典籍の画像を矩形で区切ると、システムに登録された文字矩形画像との類似性に基づき文字の推定が可能となった。システムの基本的な機能の開発は完了したが、文字解析機能の精度を高めるためには、より多くの矩形化された文字データの登録が必要となる。継続して所蔵資料の登録作業に取り組むとともに、人文学オープンデータ共同利用センターによる「日本古古典籍データセット」並びに「日本古典籍くずし字データセット」を利用して字書の充実を図った。30 年度末時点でデジタル化が完了した本学所蔵資料の総数は、画像点数 6,429 点、「文字切り出し」による文字矩形画像点数は 216,162 点である。また、人文学オープンデータ共同利用センターにより提供された「オープンデータセット」から登録された画像点数は 181 点、切り出された文字矩形画像点数は 44,832 点である。
今後、人文学オープンデータ共同利用センターにより提供される画像登録を促進し、字書の充実を図ることにより、「古典籍の文字解析補助機能」のさらなる精度向上が見込まれる。また、「古典籍の類似字形検索機能」により、文字形象を類似性に基づいて抽出することが可能となり、近世日本の刊本の膨大な数の文字形象を対象とした研究の進展が見込まれる。本研究は所蔵資料のデジタル化とシステムの構築に多くの時間を割いてきたが、これにより、近世日本の版本の文字形象に関する研究を飛躍的に発展させるための基盤が形成された。
本研究の成果
日立製作所製高速類似画像検索システム「Enra Enra」を用いた新たなシステムの開発が完了
「古典籍の類似字形検索機能」を開発、実装
「古典籍の文字解析補助機能」を開発、実装
当館所蔵古典籍資料(貴重書および金原服部文庫資料)のデジタル化とシステムへの登録
(画像点数: 6,429 点)
当館所蔵古典籍デジタルデータより文字矩形データを切り出し(デジタル文字矩形数: 216,162 点)
人文学オープンデータ共同利用センターが提供するオープンデータから古典籍資料デジタル化データ 181 点をシステムへ登録
国文学研究資料館オープンデータから文字矩形データ、44,832 点をシステムへ登録
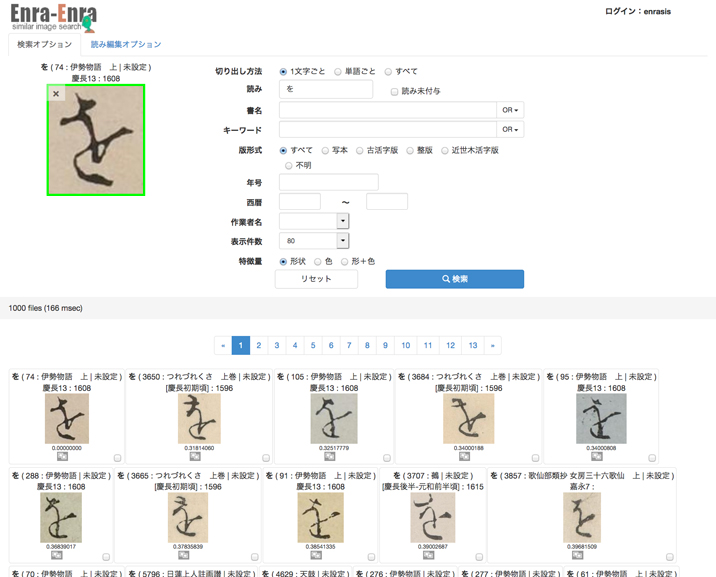 「古典籍の類似字形検索」画面
「古典籍の類似字形検索」画面
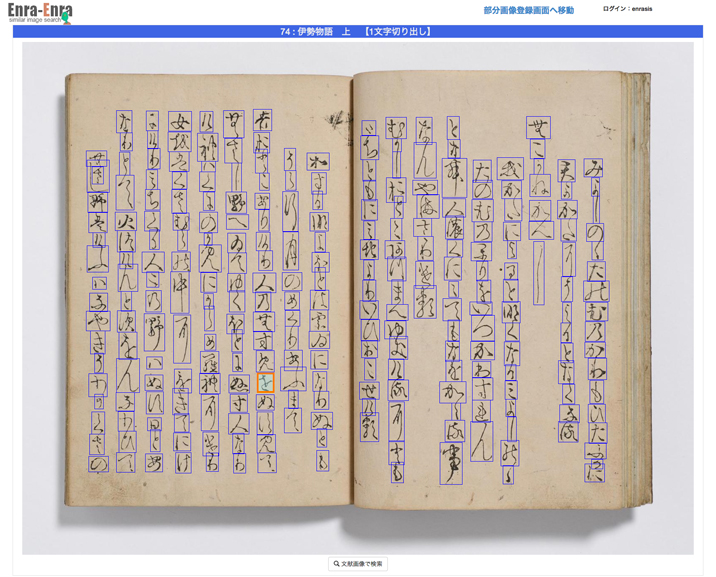 古典籍の矩形切り出し画面
古典籍の矩形切り出し画面
 「古典籍の文字解析補助」画面
「古典籍の文字解析補助」画面